



Fact: Niche copywriters are in big demand.
And they get paid more.
Why?
Because most clients aren’t just looking for any writer.
They want someone who understands their industry. Someone who can hit the ground running. Someone who can save them precious time and money.
In other words, a low-maintenance writer who just gets on with the job with minimal guidance and assistance.
So how do you make the move from a run-of-the-mill jack of all trades to a highly sought-after specialist copywriter?
That’s how this post can help.
Because it focuses on one of the most lucrative writing markets.
Together, we’ll be taking a writer’s journey into cloud computing.
We’ll be putting you in the shoes of a real cloud user. We’ll encounter some of the IT challenges they face and how the cloud helps to overcome them. We’ll be learning practically everything a writer needs to break into this highly rewarding sector.
But, before we jump in, let’s get a rundown of what we cover in this post.
What’s in This Post?
![]() The Basics of Cloud Computing: We’ll take you through all the key cloud concepts, so you know what you’re talking about when you land your first freelance client.
The Basics of Cloud Computing: We’ll take you through all the key cloud concepts, so you know what you’re talking about when you land your first freelance client.
![]() Cybersecurity: The rapid growth of cloud computing has also opened new opportunities for writers specialising in cloud security. This introduction will give you a basic understanding of cybersecurity and how it differs in the cloud.
Cybersecurity: The rapid growth of cloud computing has also opened new opportunities for writers specialising in cloud security. This introduction will give you a basic understanding of cybersecurity and how it differs in the cloud.
![]() Big Data: The cloud has been one of the key drivers behind the explosion in big data analytics. But what exactly is big data? We’ll explain everything you need to know and show you what makes big data different from traditional database technology.
Big Data: The cloud has been one of the key drivers behind the explosion in big data analytics. But what exactly is big data? We’ll explain everything you need to know and show you what makes big data different from traditional database technology.
![]() How to Find Freelance Writing Gigs: In this section, you’ll get a few starting points on where to look for your first cloud computing client.
How to Find Freelance Writing Gigs: In this section, you’ll get a few starting points on where to look for your first cloud computing client.
Who Should Read This?
This post is aimed at writers interested in becoming a cloud content specialist.
But it’s also useful to:
- Cloud service providers (CSPs) who need a fast-track guide for new in-house writers.
- Sales and marketing professionals who already work in the sector but want a deeper understanding of the cloud.
- Technical PR consultants with clients in the cloud industry.
- Senior-level IT managers looking for a broad overview of the cloud.
- Developers and operators who aren’t yet familiar with the cloud model of IT.
10 Essential Computing Terms
To make this post accessible to readers at any level, we’ve included a list of basic IT terms that are essential to your understanding of the cloud. If you’re already computer savvy, just move straight onto the next section.
(You’ll also find internal links throughout this post, so you can refer back to this glossary at any time.)
Show this sectionHide this section
The following is a quick reference list for absolute beginners in IT. Don’t worry if you forget some of the terms, as we link back to them at various points throughout the post.
1. Development
The collective process of developing software – covering everything from specification and application design to writing code (programming), testing and bug fixing.
IT people also use the term development to refer to the department or team that develops and maintains applications.
2. Operations
The people and processes involved in ensuring the smooth running of computer systems.
The role of operations would typically include taking backups, monitoring system performance, maintaining printers, providing helpdesk support and scheduling batch jobs, such as monthly salary or customer billing runs.
The term operations can also refer to the various internal tasks that a computer performs.
3. Server
A computer program that performs a specific task, providing a service to other computers or end users.
A common example is a web server. Whenever you view a web page over the Internet, your browser sends a request to a web server, which responds by serving up the web page.
Often the physical computer that hosts a server program is also called a server.
4. On-Premises Data Centre
A company’s own IT facilities, which include in-house servers, network infrastructure and the buildings it uses to house them.
The on-premises data centre characterises the traditional approach to IT. This contrasts with cloud computing, where you use an external cloud provider to host your applications instead of using your own facilities.
5. Memory
In simple terms, memory is a high-speed storage component of a computer designed to hold information for temporary use. Data is only stored in memory for as long as your computer needs it to perform a specific function – such as loading an application or web page in your browser.
Other terms used to refer to memory include primary storage, main memory and random-access memory (RAM).
6. Storage
A secondary memory component for retaining information over long periods. Whether used or not, data maintained in storage remains there until it’s actively deleted.
Storage media are designed to hold far more data than memory. But they come with a trade-off of slower access speed.
The two main types of storage are the hard disk drive (HDD), which uses traditional magnetic media, and solid-state drive (SSD), which is based on newer microchip technology. SSD storage is faster but more expensive than HDD.
Units of Measure
Storage and memory are generally measured in:
- Gigabytes (GB): 1GB is slightly more than the storage capacity of a compact disc (CD).
- Terabytes (TB): 1TB = 1,024GB. This is slightly more than the storage capacity of 200 DVDs.
- Petabytes (PB): 1PB = 1,024TB. Slightly more than the capacity needed to store 2,000 years of MP3 recordings.
Petabytes are generally used to refer to the storage capacity of large computer networks rather than individual machines or components.
7. Central Processing Unit (CPU)
The CPU is both the workhorse and intelligent component of your computer.
It executes the instructions given to it by the programs running on your machine. It performs calculations and logical operations. It accepts input from devices, such as a keyboard or mouse. And it also relays signals between other hardware components in your computer.
A number of factors determine the performance capability of a CPU. One of the most significant is clock speed, which is the operating frequency or number of instruction cycles the CPU handles each second. Clock speed is measured in megahertz (MHz).
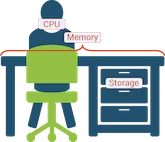
The best way to understand the difference between memory, storage and CPU is to visualise a computer as yourself working at a desk.
The surface of the desk is like computer memory, as it’s the place where you put all the things you need to perform your immediate work. The set of drawers is like computer storage, as you use it to store items away until you need them. And you are the CPU, as you’re the one doing the work at the desk.
8. Command-Line Interface (CLI)
A method of interacting with a computer using text-based commands.
Until the late 1980s virtually all computers used a CLI. But, since the arrival of macOS and Windows, it has been largely superseded by the graphical user interface (GUI) – the familiar desktop method by which we access our computers using icons and other visual indicators.
Nevertheless, CLIs are still widely used by developers. This is because they’re quicker and more convenient for performing technical tasks, such as configuring your machine, working with programs and managing workflows.
You can still access the CLI on modern home computers. Windows supports two CLI applications – Windows PowerShell and the older Command Prompt. The CLI tool provided in macOS is known as Bash, which you can access via the Terminal application.
The following is a screenshot from a Bash terminal session on a Mac:

9. Open-Source Software
Many applications are built using a type of computer code known as a compiled language. Whenever a developer creates a program using one of these languages, they have to compile it before they can run it. This process converts their source code into a lower-level machine language the computer can understand.
Proprietary software, such as Microsoft Office and Adobe Creative Suite applications, keep their source code secret and only provide you with the compiled code.
But open-source software is different. You can access and modify the source code, allowing you to adapt the software to work the way you want.
Open-source products are typically the result of community-oriented projects, by which software is developed, tested and improved through collaborative participation. This often makes them more robust and secure than proprietary alternatives.
Most open-source software is free to use. However, some enterprise-grade products, which offer extra features such as customer support and enhanced functionality, are licensed on a subscription basis.
10. Linux
An operating system just like Windows and macOS. It can run on pretty well any kind of hardware, including PCs and Macs, and is the underlying technology behind a vast array of devices – from Android phones and TVs to home appliances, web servers and the world’s fastest supercomputers.
Linux has become the platform of choice for application development because it is open source, free to use and highly flexible, stable and secure.
It also comes in different versions known as distributions. Each distribution uses the same core Linux operating system, but may be geared towards a particular type of hardware or different goal.
For example, Ubuntu puts a strong emphasis on ease of use, Debian leans towards quality control and Fedora focuses on innovation and compatibility with the latest technologies.
Further Reading
Do you want to learn how to use the Linux command line? Or maybe just want to get a feel of how it works?
The Linux Command Line by William Shotts is a complete introduction to the CLI, taking you from an absolute beginner right through to a Linux power user.
It’s more of a guided tour than a technical manual, with topics organised into digestible bite-size chunks. Packed with practical examples, it’s both great fun and ridiculously easy to read.
You can purchase the book at No Starch Press or get the PDF version for FREE using this download link.*
* This recommendation does NOT contain affiliate links.
What Is Cloud Computing?
Difficulty level
Cloud computing is a HUGE business.
The industry is growing exponentially and offers a wealth of opportunities for tech-savvy writers and bloggers.
But what exactly is the cloud?
Many people think of it in terms of file storage services, such as Dropbox or iCloud.
But they’re only a tiny part of it.
These services belong to a category of applications known as Software as a Service (SaaS) – which represents just one layer of the cloud as a whole.
To see the bigger picture, we need to go back to the time when the cloud first started.
How the Cloud Began
Remember the dot-com revolution of the late 1990s and early 2000s?
Online shopping giant Amazon was fast becoming a global retail empire, with a rapidly expanding product catalogue, customer base and network of merchant partners.
One of the biggest challenges the company faced was how to expand its server network fast enough to meet the huge growth in demand.
As a result, infrastructure development became central to Amazon’s business plan. It took a new shared approach to IT architecture, which helped to minimise unused server resources. And it developed a platform that could scale quickly, easily and cost effectively.
Then Amazon started to realise other businesses could benefit from its new model of IT.
So it set up the subsidiary company Amazon Web Services (AWS) with the goal of delivering this vision. Companies would then be able to use the retailer’s IT infrastructure to host their own workloads. They’d be able to provision exactly the resources they needed instead of purchasing or renting an entire server. And they’d also be able to scale their computing resources quickly and easily to meet demand.
In 2006, the eCommerce giant then officially launched the first service that we know as public cloud today. This was initially just online storage but other computing services quickly followed.

(Image source: Steve Jurvetson)
Although the concept of the cloud had dated back to the 1960s, the arrival of AWS marked an important turning point, where the term cloud computing came into widespread use.
The difference between AWS and traditional types of server hosting wasn’t the physical hardware itself but rather the way in which the service was delivered.
This new model of cloud computing was characterised by the following features:
- Self-service: You can access, modify and manage your IT resources on demand without involvement of the cloud service provider – either through a web-based console or the CLI.
- Pay as you go (PAYG): You only pay for the resources you use and receive a monthly bill based on your metered consumption.
- Elastic: You can scale your resources up or down quickly and easily as your needs change.
Cloud computing is the on-demand delivery of IT resources over the Internet with pay-as-you-go pricing.
– Amazon Web Services (AWS)
The Big Three Cloud Providers
AWS
The first and by far the largest cloud service provider in the world. It is also the most sophisticated cloud offering, with a choice of services and features to meet virtually any IT requirement.
The platform is strongly oriented towards the self-service concept of the cloud and has a very similar look and feel to the parent company’s retail website. If you start writing about the cloud, much of your focus will be on AWS.
Microsoft Azure
The strongest challenger to Amazon’s dominance of the public cloud market. The platform offers strength in depth and is a particularly good fit for businesses that already use other Microsoft technologies.
Microsoft’s approach to service delivery reflects the company’s heritage as a traditional computing service provider, generating much of its business through product bundling and an established network of sales representatives.
Google Cloud Platform
Google is a relative newcomer to the public cloud marketplace and doesn’t yet offer the same scope of services as its two main competitors.
Nevertheless, the vendor has built up a strong customer base on its core strength of innovation. It leads the way in many cutting-edge technologies, such as big data, analytics and machine learning. Like Amazon, Google’s offering is highly geared towards its self-service online portal.
Three Delivery Models of the Cloud
As you learn and write more about the cloud, you’ll frequently come across the terms Infrastructure as a Service (IaaS), Platform as a Service (PaaS) and Software as a Service (SaaS).
These represent the three basic categories or delivery models of cloud computing.
They’re also known as the three layers of the cloud, as each category of service sits on top of the other, as follows:
![]() Infrastructure as a Service (IaaS): A category of cloud service, which provides you with the basic building blocks, such as servers, storage, networking resources and an operating system, for building your own virtual data centre in the cloud.
Infrastructure as a Service (IaaS): A category of cloud service, which provides you with the basic building blocks, such as servers, storage, networking resources and an operating system, for building your own virtual data centre in the cloud.
All you really get is the raw ingredients for hosting your applications and that’s it. It’s down to you to configure and maintain your cloud environment – just as you would if it were your own on-premises data centre.
IaaS offers you the freedom to customise your infrastructure to work the way you want. This is often important when you migrate existing applications to the cloud, as you may need to replicate your on-premises operating environment to make sure they work.
Cloud service providers supplement their IaaS offerings with tools to manage your infrastructure. These include cost-monitoring, security, storage and backup and recovery services, many of which are also offered by third-party cloud partners.
![]() Platform as a Service (PaaS): The second major layer or category of cloud service, built on top of IaaS, which provides developers with a pre-configured, fully managed environment for deploying code.
Platform as a Service (PaaS): The second major layer or category of cloud service, built on top of IaaS, which provides developers with a pre-configured, fully managed environment for deploying code.
PaaS speeds up the process of building applications by providing the frameworks developers need, such as a database management system or web server, for deploying their software. As a result, developers only need to worry about their code – without the headache of system configuration and maintenance.
Some types of PaaS offering allow under-the-hood access to your underlying resources, such as the type and capacity of your storage. But others are serverless, where you don’t have any involvement with the underlying infrastructure.
Despite the clear advantages, deploying your applications to PaaS increases the risk of vendor lock-in. This is where you become tied to a particular platform because of the difficulties involved in moving to another cloud vendor.
![]() Software as a Service (SaaS): The layer of the cloud we’re most familiar with, encompassing a vast array of new-generation applications and services, such as Dropbox, iCloud, Netflix, Microsoft Office 365 and Adobe Creative Cloud.
Software as a Service (SaaS): The layer of the cloud we’re most familiar with, encompassing a vast array of new-generation applications and services, such as Dropbox, iCloud, Netflix, Microsoft Office 365 and Adobe Creative Cloud.
SaaS applications are cloud-based software built on top of either PaaS or directly on top of an IaaS environment. SaaS providers manage their applications centrally and grant access to their services over the Internet on a PAYG subscription basis.
SaaS applications typically use a multi-tenant design, whereby a single instance of the software serves more than one customer at the same time. This contrasts with the traditional single-tenant model – where you purchase your own copy of the software and install it on your machine for your own exclusive use.


Key Cloud Computing Concepts
Difficulty level
Now we’re going to dig deeper into how the cloud actually works.
Let’s do this by running through some of the key cloud concepts:
Virtualisation
By and large, when you develop a new application, it’s good practice to deploy it to a separate physical server.
You do this for a number of reasons.
For example, if you host all your workloads on a single server they compete for resources. So if one application experiences a spike in CPU or memory consumption, it will slow down everything else running on the same server.
What’s more, if one application crashes and you need to reboot your machine, all other applications go down with it.
Using different servers also isolates your applications, which can help reduce the spread of malicious damage in the event of a security breach.
But all this comes at a cost.
Many servers end up being underused, wasting computing resources.
To overcome the issue, a new technology emerged known as virtualisation.
This involves breaking up one larger physical machine into a number of smaller virtual machines – where the underlying physical machine is known as the host and the virtual machines known as guests.
Each virtual machine is an isolated operating environment with its own allocated storage, memory and processing capacity. It has its own operating system and works just like an actual physical computer or server.
The concept of virtualisation is familiar to many Mac owners who use emulation software, such as Parallels Desktop and VMware Fusion.
These applications allow you to run Windows or Linux as a virtual machine within your Mac without rebooting it.

Virtualisation also comes in other forms. For instance, storage virtualisation unifies storage from completely separate physical devices into what appears to be a single storage appliance. However, server virtualisation is currently the most common example of the technology.
Hypervisor
The software that creates, runs and manages virtual machines. There are two broad categories of hypervisor:
- Type 1 (native/bare metal): The software runs directly on the host hardware.
- Type 2 (hosted): The software runs on the host operating system.


Instance
An instance is basically another name for a virtual machine. By and large, you can use the terms interchangeably. However, the term instance is far more strongly associated with the cloud.
Instances are one of the core services provided by public cloud vendors. They’re available in a wide variety of machine types, each with different amounts of CPU and memory suited to different price points and applications.
Some types of instance provide integrated local storage, which comes as part of the machine. These specialist instances are targeted at applications where fast access to storage is essential. However, local storage is temporary, existing only as long as the instance is running.
With other types of instance, you have to purchase external storage separately.
Cloud service providers organise their instances into groups of different-sized machines, which share similar performance characteristics.
For example, general-purpose instances provide a balanced mix of CPU and memory. By contrast, compute-optimised instances are aimed at applications that use a lot of processing power and come with a higher proportion of CPU.

You can manually launch an instance in two different ways – either through your cloud provider’s online portal or through their command-line interface (CLI).
Once you’ve launched your machine, and it’s up and running in the cloud, you’ll need to set up a connection to it.
You do this using a program on your computer known as an SSH client, which allows two computers to communicate with each other over a secure connection.
Cloud vendors provide you with the details you need to connect to your virtual machine, which include the IP address and SSH access credentials for the instance.
Learn More
Want to see how you launch and connect to an instance in practice? Then check out this YouTube video, which shows you how to spin up and connect to an Ubuntu instance on AWS:
By default, you communicate with your instances via the CLI. However, it’s also possible to access a virtual machine through a graphical-user interface (GUI) by using what’s known as remote desktop client software.
Machine Image
Imagine you could buy a home computer with all the applications and settings you want already configured and good to go.
Just think how much time you’d save.
You wouldn’t have to waste hours installing Microsoft Office, Adobe Acrobat Reader, Firefox, antivirus software, printer drivers or whatever else you need.
Machine images solve a very similar problem for public cloud users.
They help developers hit the ground running by allowing them to launch an instance that’s preconfigured with the operating environment they need to build their applications.
Basic machine images simply provide the operating system – usually either a Linux or Windows server. Some come preinstalled with a database management system. Others come with a full application stack that’s available for immediate deployment – such as a ready-to-use WordPress installation or eCommerce platform.
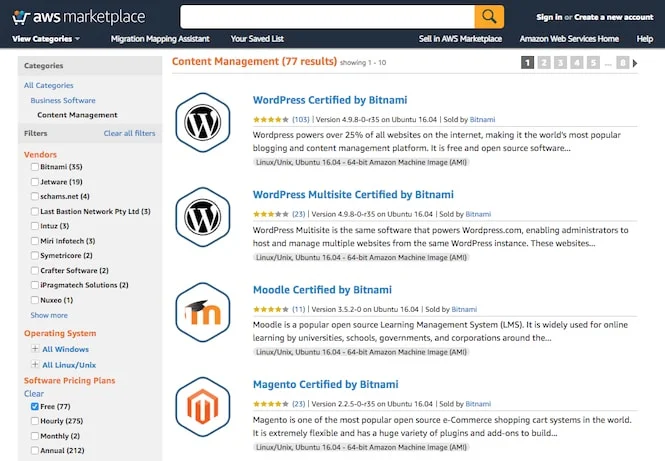
In simple terms, a machine image is a snapshot or static copy of a virtual machine, which you can use as a template for creating new live instances.
You can create snapshots of your own instances and use them as machine images. You can then use them to replicate the same operational setup over and over again.
This can play a particularly useful role in system backups. Because if your instance fails you can replace it with a new one based on the same machine image.
Microservices
A new distributed approach to application design that’s particularly well suited to the cloud.
Whereas traditional applications run on a single system, modern cloud applications are broken up into a series of smaller tasks known as microservices, each deployed to their own virtual machine.
Containers
It’s also possible to deploy microservices to even smaller server environments known as containers. Containers are an emerging technology that use an alternative virtualisation approach to virtual machines.
You can tailor each virtual machine to the resource consumption of the specific microservice. For example, one task may consume a lot of memory, requiring a large memory-optimised instance. Another may have only modest resource overhead, requiring only a small general-purpose machine.
You can also allocate the same microservice to more than one virtual machine and use a device known as a load balancer to distribute requests across your group of target instances.
This speeds up your application by allowing it to serve more than one user at the same time. It also improves the resiliency of your application, as it can continue to serve requests if one of your microservices fails and needs a server reboot.

Vertical Scaling
Remember how we said you could scale your cloud resources quickly and easily as your requirements change?
Well, you can do this in two different ways – either vertically or horizontally.
Vertical scaling means moving your workloads to larger or smaller virtual machines. This tends to be a more expensive scaling approach, as you’re tied to your cloud vendor’s fixed set of machine sizes. As a result, you often have to switch to a much larger machine just to accommodate a modest additional load.
What’s more, you can only scale up to the largest instance size available, which isn’t much use if you have applications that handle particularly large workloads.
Nevertheless, vertical scaling is the only viable option for many older applications that were designed to run on a single machine.
Horizontal Scaling
A method of scaling your infrastructure by adding or removing machines.
Horizontal scaling lends itself particularly well to modern distributed applications made up of smaller microservices deployed to separate virtual machines.
It is generally more cost-efficient than vertical scaling, as you can host your application on a network of smaller instances and scale in or out by much smaller increments. This gives you finer control over your resources and helps reduce your expenditure on unnecessary infrastructure.
Most cloud vendors support auto scaling – a horizontal scaling feature, which automatically increases or decreases the number of instances in your cluster as the load on your application changes.


Advantages of the Cloud
OK, we now understand the basics of cloud computing.
But why exactly is it so popular?
Let’s check out the main advantages it has to offer:
|
|
Lower Barrier to EntryYou don’t have to invest in expensive hardware to host your applications. So the financial risk of starting new IT projects is much lower. This makes the cloud particularly appealing to business start-ups and also helps drive innovation. |
|
|
Faster DevelopmentIt can take weeks or months to procure new on-premises hardware. But you can provision cloud infrastructure at the click of a button. Moreover, the cloud has spawned a large ecosystem of new software development technologies. These are helping companies to build applications more quickly and efficiently, giving them a competitive edge over traditional IT users. |
|
|
Reduced Running CostWhen you purchase an on-premises server, you have to make provision for spikes in demand and future growth. So you typically end up buying hardware with far greater capacity than you generally need. But, with the cloud, you just pay for what you need at any given time and only purchase extra capacity for temporary peaks in demand. This makes it a more efficient way to consume IT. |
|
|
High Availability and ReliabilityIf a centipede loses a leg, it still has plenty more to fall back on. Public cloud platforms work in a similar way. They use highly resilient distributed designs to ensure that, when a server goes down, their services continue to operate normally. By contrast, on-premises systems typically share the load between far fewer physical machines. This makes them more vulnerable to failure and lengthy downtime. What’s more, unlike traditional computer programs, you can roll out software updates and patches to a distributed cloud application without shutting it down completely. |
|
|
Better SecurityThe leading cloud vendors have a wealth of security expertise at their disposal – far more than most companies can ever hope to provide in-house. That means they can offer more advanced protection than traditional IT environments through robust frameworks for securing your infrastructure. |
Disadvantages of the Cloud
For all the benefits of cloud computing, it still comes with a few drawbacks:
|
|
Complex ManagementIn a traditional on-premises data centre you only have to manage a relatively small number of servers. But cloud infrastructure is altogether different. It is a complex and dynamic IT environment, where users are continually spinning up, scaling and closing down instances as well as accessing other services, such as storage, load balancing and databases. They can easily rack up unnecessary costs by forgetting to shut down unused resources or provisioning far more infrastructure than they actually need. Operations and security teams can overlook the warning signs of a possible malicious attack. And failed backups can go unnoticed. To maintain visibility over the complex array of moving parts, many cloud users have to invest in sophisticated monitoring tools to keep a lid on costs, manage system performance and protect their data. |
|
|
Slow PerformanceA fast and reliable network connection is essential to the optimal performance of cloud-based applications – something the public Internet cannot guarantee. To overcome the problem, some customers use a dedicated network connection. This provides a faster, more reliable and more secure connection directly between their cloud and on-premises data centre. However, a dedicated network is far too expensive for most small-scale cloud operations and can only improve the performance of applications that rely on internal network traffic. Another reason for slow cloud performance is poor application design. This often happens when companies migrate their on-premises applications directly to the cloud without adapting them to suit their new operating environment. |
|
|
Vendor Lock-InEach cloud platform has its own specific protocols and technologies, which often make it difficult to switch to another provider. Not only that, but they also charge for transferring data out of their clouds. So customers may still feel tied to the same vendor, even in cases where switching is relatively simple. |
More Cloud Essentials
Difficulty level
Skip this section
Let’s finish our introduction to the cloud by exploring a few more important concepts.
Failover
Failover is an operational backup measure that can help keep your systems running in the event of a cloud service outage.
Although the leading cloud providers maintain levels of service availability few in-house IT departments can match, service interruptions can and do still happen.
So, to maintain business continuity, mission-critical applications such as banking systems and large online retail stores use failover mechanisms that switch to a secondary standby cloud environment if their primary infrastructure fails.
Different applications use different types of failover architecture depending on:
- Cost: A highly resilient and complex failover architecture is generally more expensive than a basic standby system.
- Downtime: Some use cases will require 100% availability whereas others can tolerate a small amount of downtime to allow for recovery.
- Performance: The secondary environment may have to meet the same level of performance as the primary system. Alternatively, it may be able to tolerate lower performance, as long as the application remains fully functional.
Cloud vendors provide the means for failover through globally distributed networks of regions and availability zones.
Regions are geographical groupings of data centres based in different physical locations across the world.

Each region is made up of several physically separate data-centre locations known as zones or availability zones.

Cross-region failover, where you replicate an application across two different regions, provides a higher level of fault tolerance and stability than replication across two availability zones in the same region.
However, it is more expensive. This is down to the cost of data transfer, which is generally higher between regions than between availability zones within a region.


DevOps
DevOps is a concept that’s pretty hard to grasp at first. But, basically, it’s a new approach to IT that brings operations and development more closely together towards a common goal.
The role of operations is to keep IT systems running smoothly. The role of development is to push out new software, introducing new services and features as quickly as possible.
But new software releases can be an operational headache, as they potentially undermine the stability and security of live computer systems. At the same time, development teams often feel innovation is being stifled by operations.
DevOps sets out to resolve the conflicting aims and objectives of the two IT functions – through a shared purpose of faster software development and improved application performance, security and reliability.

The cloud and DevOps have a strong natural relationship with one another. This is because the architecture of cloud-based applications (the domain of development) is so closely intertwined with the underlying infrastructure (the domain of operations).
Cloud vendors provide access to a wide range of tools to support DevOps practices. These come under a variety of different categories, which include:
|
|
CollaborationSolutions that facilitate communication, teamwork and project management in the planning, design, coding, testing and deployment process. |
|
|
Continuous Integration (CI)Code integration systems where developers working on the same project can merge their code changes into a central repository for regular testing. This makes it quicker and easier to identify bugs and coding conflicts, which become increasingly more difficult to resolve when coders work for longer periods in isolation. |
|
|
Continuous Delivery (CD)Automated software release systems that reduce the manual work involved in deploying new code to testing and live environments. |
|
|
Infrastructure as Code (IaC)Automated procedures that use templates for provisioning and managing infrastructure. You can use IaC tools to configure machine images and automatically roll out patches, updates and configuration changes to your servers. IaC tools help you provision and configure application environments more quickly, reliably and consistently than performing the same tasks manually. |
|
|
Continuous MonitoringProducts that help you quickly identify infrastructure and application issues that could impact the performance, security or stability of your IT systems. |
Private Cloud
An on-premises data-centre environment in which shared pools of resources are virtualised in much the same way as the public cloud.
A private cloud offers similar benefits to the public cloud, such as self-service provisioning, ease of scaling, higher levels of automation and more efficient use of hardware.
An organisation will typically use a private instead of public cloud to:
- Meet specific security requirements
- Comply with data privacy standards
- Maintain direct control over all its infrastructure
However, building a private cloud is no easy challenge. So uptake is still relatively low compared with public cloud adoption.
Hybrid Cloud
An integrated environment of public cloud, private cloud and other on-premises infrastructure.
Hybrid cloud gives you the best of both worlds by offering more freedom to host applications based on cost, capacity, performance and regulatory requirements.
For example, workloads that handle sensitive data may be better suited to your on-premises data centre. By contrast, an application with global reach would be a good fit for the public cloud.
But one thing you should bear in mind.
Hybrid cloud isn’t simply a collective term for both public and private cloud environments. It implies some kind of orchestration or workload portability between them.

Common use cases for hybrid cloud include:
- Cloud bursting: A method by which you offload some of your on-premises workload to the public cloud during peaks in demand.
- Failover: An application architecture that uses private and public cloud as your primary and secondary environments respectively.
- Data storage: A deployment where on-premises applications use cloud-based storage, which is easy to access from any company location in the world.
Hybrid cloud is often the stepping stone to wider public cloud adoption, providing a stopgap solution as companies gradually modernise their outdated systems.
Multicloud
A wider umbrella term to describe two or more clouds that come under the same centralised management. A multicloud can be:
- Two or more public clouds: Without a private cloud.
- A hybrid cloud: A private cloud and one or more public clouds.
In other words, by definition, a hybrid cloud is also a multicloud.
Like the hybrid model, the constituents of a multicloud may be integrated in some way. However, they don’t necessarily have to be.
A multicloud environment helps you avoid the risk of putting all your IT eggs in one basket.
You’re not reliant on a single cloud vendor. You can enhance protection against downtime by using different cloud providers in your failover architecture. You can host each workload on the platform that’s best suited to your applications. And you can take advantage of the different pricing packages on offer.


Application Programming Interface (API)
The means by which an application allows other programs to access selected parts of its internal functionality.
An API is made up of two parts:
- Specification: A list of commands, known as functions, which developers can use to serve requests from other programs. Requests instruct the application to perform an action, such as retrieving, changing, adding or deleting data. An instance of a request is known as an API call, which must be in a format that conforms to the specification.
- Interface: The actual software that executes API calls in line with the specification.

APIs play a key role in the modern digital world by providing a way for different applications to talk to one another.
For example, leading Internet players, such as Google, Facebook and Twitter, publish APIs so third-party developers can build applications and integrations that plug into their websites.
APIs are also a core component of the public cloud, allowing users to manage their cloud infrastructure programmatically through API calls from within their applications.
API Key
An API key is a form of secret token that some APIs use to authenticate requests. Their main purpose is to help prevent unauthorised users from gaining access and making changes to your data.
Cybersecurity
Difficulty level
Skip this section
Technology is everywhere. And we’re using more and more of it.
But more technology also means more opportunities for cybercriminals.
As a result, the growth of cybercrime has been relentless. And it’s now costing the global economy trillions of dollars every year.
At the same time, the supply of cybersecurity skills is struggling to keep up with demand. According to recent estimates by security training and certification body ISC2, the worldwide shortage of cybersecurity professionals is rapidly approaching three million.
That’s a serious shortfall. But great news if you want to work in the cybersecurity industry – including freelance writing.

(Image source: ISC2)
This section is a beginner’s guide to cybersecurity. It focuses on the knowledge you’ll need to take on your first writing assignment, as well as highlighting the key differences between on-premises and cloud-based security.
What Is Cybersecurity?
Cybersecurity is very broad in scope, ranging from very simple everyday protection measures, such as enforcing strong password policies, to advanced forensics requiring detailed knowledge of cryptography, computer networks, coding languages and operating systems.
However, all aspects of cybersecurity share a common aim – to prevent malicious damage through unauthorised access to computers, servers, mobile devices, networks and electronic systems.
The foundations of any robust cybersecurity strategy are made up of three essential components. These are:
![]() PeopleCultivating a security mindset across your workforce by educating employees about their role in countering cyberthreats. For example:
PeopleCultivating a security mindset across your workforce by educating employees about their role in countering cyberthreats. For example:
- Computer users should be aware of their everyday responsibilities, such as reporting suspicious email attachments and keeping sensitive data and login credentials confidential.
- Developers need to be aware of potential coding exploits and build resilience into their applications.
- Operations teams should enforce tight control over user access and privileges.
- Specialist cybersecurity staff need to keep up to date with the latest skills and cyberthreats.
![]() ProcessesDeveloping, documenting and implementing appropriate security policies, frameworks and procedures. These typically include:
ProcessesDeveloping, documenting and implementing appropriate security policies, frameworks and procedures. These typically include:
- Classifying your data to help identify the level of protection it requires.
- Maintaining an identity and access management (IAM) policy that limits access rights only to the systems and data users actually need.
- Keeping systems up to date with the latest security patches.
- Adopting a backup and recovery strategy to prevent data loss in the event of an attack.
![]() TechnologyProviding the tools you need to secure your infrastructure, such as:
TechnologyProviding the tools you need to secure your infrastructure, such as:
- Monitoring and alerting tools to help you detect potential attacks.
- A firewall to prevent unsolicited traffic from entering or leaving your network.
- Automated workflows for deploying coding updates and managing configurations.
- A physical backup and recovery system.
So now we’ve got the high-level overview out the way, let’s delve a little further.
Key Cybersecurity Concepts
The following are a few selected concepts to give you a feel for how cybersecurity works in general. They are equally important to both on-premises and cloud-based security.
Password Hashing
A one-way cryptographic process that converts a password into an unreadable string of characters known as a hash. A good hashing algorithm will make it virtually impossible to convert a hash back to its original password.
To make login systems more secure, password files only store passwords in hashed form.
Whenever you enter your password on a website, the login system simply hashes it again and checks it against the version stored in the password file. If the two hashes match then it knows you’ve entered your password correctly.


Brute-Force Attack
A trial-and-error method of gaining unauthorised access to systems, where a hacker makes repeated login attempts using different combinations of characters until they eventually hit upon the correct password, username or PIN.
But this can take a HUGE amount of manual time and effort.
So hackers use automated cracking software, which can perform more than a million guesses in just a second on a standard home laptop alone. Specially designed machines can run through billions of permutations a second.
Login systems usually incorporate security measures to prevent brute-force attacks – such as locking you out after several unsuccessful login attempts or using some form of CAPTCHA test that disrupts the ability of robots to complete online forms.

To get around this, hackers need to steal the target password file first and then launch the brute-force attack offline.
They also need to know what type of hashing function the login system uses. They can usually tell this from the length of the hashes. Alternatively, they may set up a dummy account and use the resulting hash to work out which algorithm created it.
As password cracking is time-consuming and highly resource intensive, many hacking tools go for the low-hanging fruit before progressively working through all other combinations. For example, they may draw on:
- Dictionaries: Where the application tries every word in a list compiled from the dictionary.
The dictionary technique is often successful because so many people use everyday words that are easy to remember.
- Rainbow tables: A huge and complex hash-reversing table, which the software uses to find plain-text possibilities that correspond to a hash.
Rainbow tables save having to hash each possible password, as the work has already been done in the table.
- Common patterns: Using searches for common phrases and predictable keyword combinations, such as letmein, qwerty and 44556611.
They can also exploit patterns in passwords with mixed upper-case, lower-case and numeric characters, such as Mercedes77, Wyoming41 and Watermelon53, which all start with a capital letter and end with two digits.
The longer your password and the more variation of character types, the longer it will take a hacker to crack it. And that means they’re far likelier to give up and move onto easier targets.
| Maximum Time to Crack a Password by Brute Force (At 15 Million Attempts per Second) |
||
|---|---|---|
| Length | Complexity | Time |
| 4 | a–z | < 1 second |
| 4 | a–z, A–Z, 0–9 + symbols | 4.8 seconds |
| 5 | a–z, A–Z | 25 seconds |
| 6 | a–z, A–Z, 0–9 | 1 hour |
| 6 | a–z, A–Z, 0–9 + symbols | 11 hours |
| 7 | a–z, A–Z, 0–9 + symbols | 6 weeks |
| 8 | a–z, A–Z, 0–9 | 5 months |
| 8 | a–z, A–Z, 0–9 + symbols | 10 years |
| 9 | a–z, A–Z, 0–9 + symbols | 1000 years |
| 10 | a–z, A–Z, 0–9 | 1700 years |
| 10 | a–z, A–Z, 0–9 + symbols | 91,800 years |
| Data source: TopLine Strategies | ||
You should also avoid using the same password across each of your online accounts. Because once a hacker obtains the login details to one of your accounts they’ll have easy access to others.
Password management tools, such as Bitwarden and 1Password, provide a secure central repository for storing all your different login credentials. They also offer security features, such as strong password generation and two-factor authentication (2FA).
A 2FA system secures your password vault by requiring an additional login step, such as entering a PIN sent to your mobile phone. This stops hackers from gaining access on the basis of your username and password alone.
Private-Key Encryption
A two-way cryptographic process that uses an encryption key to convert an electronic message into an unreadable string of characters known as ciphertext. The recipient can then convert the message back to its readable form using the same key.
Private-key encryption is highly efficient and plays an important role in securing communication over the Internet. However, the technology is rarely used in isolation.
This is because both parties would first need to exchange the key over an unsecured connection. A hacker could potentially gain access to the key by intercepting the initial exchange. They could then use it to decrypt messages as well as encrypt and send new ones as if they were one of the original two parties.


Private-key encryption is also known as symmetric encryption and secure-key encryption.
Public-Key Cryptography
A two-way cryptographic system that uses two types of key: a public key and a private key.
You can share your public key with anyone. But private keys are always kept secret.
Both the public and private key can perform encryption. However:
- When someone encrypts a message using your public key: Only your private key can decrypt it.
- When you encrypt a message using your private key: Anyone with your public key can decrypt it.
These properties provide the basis of three very important applications of public-key cryptography: public-key encryption, digital signatures and digital certificates.
Public-Key Encryption
With public-key encryption, two computers simply exchange each other’s public keys to set up a secure connection.
To send someone a message, your computer encrypts it using the recipient’s public key. That message can be sent securely over an open network because only the intended recipient’s private key can decrypt it.
In the same way, when someone sends you a message, their computer uses your public key – safe in the knowledge that only your private key can decrypt it.


Public-key encryption plays an important role in the HTTPS protocol used by secure websites. Whenever you visit an HTTPS site, the web server and your browser automatically initiate a secure session by exchanging public keys in the background.
However, public-key encryption comes with a downside.
It’s far more complex and resource intensive than private-key encryption. So it’s only used at the beginning of the session to exchange a unique one-time symmetric key between the two parties. This is then used for faster private-key encryption throughout the remainder of the message sequence.
Public-key encryption is also known as asymmetric encryption.
Digital Signature
A digital signature is a cryptographic technique used to verify a digital document, message or piece of software belongs to the person or organisation that created it.
It can also confirm the integrity of content by proving it couldn’t have been altered since it was originally created.
Digital signatures use the other important property of public-key cryptography – the fact that, when you encrypt a message using your private key, anyone with your public key can decrypt it.
The signing process works by:
- Converting the content into a hash
- Encrypting the hash using the owner’s private key to create the digital signature
- Appending the signature to the plain-text version of the content


The verification process works by:
- Converting the plain-text version of the signed content into a hash
- Obtaining the hash from the digital signature appended to the content by decrypting it using the owner’s public key
- Comparing the two hashes


If the two hashes are the same then the signature is valid. This match shows the signature was generated using the private key that corresponds to owner’s public key. Otherwise you’d end up with a different hash value when you decrypt it.
If the hashes don’t match then either:
|
|
The owner isn’t who they claim to be: Because the private key they used isn’t linked to the public key they presented. |
OR
|
|
The content has been tampered with since it was signed: Because the digital signature is unique to the original content. If you used it to sign a document with even the slightest alteration, such as a change to a single letter, the two hashes would be totally different. |
Finally, remember how we said public-key encryption is far more complex and resource intensive than private-key encryption?
Well, likewise, it’s much slower and more complex than a one-way hash function.
Moreover, hash functions convert the content into a fixed-length value. This is usually much shorter than the original plain-text version.
That’s the reason for hashing the content first – because it reduces the load of encrypting and decrypting a potentially much larger document, message or piece of code.
Digital Certificate
A digital certificate provides a way to check the owner of a public key is, in fact, the person or organisation they claim they are.
 Digital certificates are used by all HTTPS websites and include the following information:
Digital certificates are used by all HTTPS websites and include the following information:
- Website owner’s public key
- URL of the website
- Digital signature of the issuer (the certificate authority)
- Details of the certificate authority that issued it
- Date from which it became valid
- Date on which it expires
What Is a Certificate Authority?
A certificate authority or certification authority (CA) is a trusted third party that manages and issues digital certificates and public keys.
Widely recognised examples of CAs include Thawte, GeoTrust and Sectigo. Some CAs only provide digital certificates and related services while others provide a wide range of security products, such as antivirus software and firewalls.
Anyone can effectively become a CA and issue digital certificates. So web browsers maintain lists of digital certificates belonging to those CAs they trust. These are known as root CAs.
Browsers will only trust HTTPS websites with a digital certificate that has either been signed by a root CA or by an intermediate CA whose own digital certificate has been signed by a root CA.
CAs issue digital certificates by creating a plain-text version of the certificate content and signing it with their own private key.
Whenever you visit a HTTPS website, the first thing your browser does is verify the digital certificate. In simple terms, it performs the following steps:
- Checks the website address matches the address in the certificate
- Checks the period during which the certificate is valid
- Checks the issuer of the certificate is in its list of root CAs (or is an intermediate CA whose own digital certificate has been signed by a root CA)
- Converts the plain-text version of the certificate into a hash
- Fetches the public key from the CA’s own digital certificate
- Obtains the hash from the CA’s signature in the digital certificate for the website by decrypting it using the CA’s public key
- Checks the two hashes for a match


A digital certificate helps prevent man-in-the-middle attacks. This is where an attacker attempts to intercept your secure connection to a web server and impersonate the website by presenting a bogus certificate containing their own public key.
However, your browser would reject it, because it only accepts certificates signed by CAs it trusts.
This process forms part of what’s known as an SSL/TLS handshake, which is performed every time you connect to an HTTPS website. The handshake involves several other initialisation steps, which include exchanging public keys and a shared one-time symmetric key.
A digital certificate is also known as a public-key certificate and identity certificate.
As a cybersecurity writer, you wouldn’t be expected to know the inner workings of a cryptographic algorithm.
All the same, it’s useful to have a basic idea of the underlying principle. In other words, the maths that makes it practically impossible for a hacker to work out the private key from the corresponding public key.
In simple terms, the private key consists of two prime numbers (numbers that can only be divided by 1 or themselves, such as 3, 5, 7, 11 and 13) while the public key is generated from the result of multiplying these two numbers together. The prime numbers are referred to as factors and the result of the multiplication is known as the product.
The security of the algorithm relies on the fact that:
- The prime numbers used in the private key are very large.
- When you multiply two such numbers (to create the public key) you end up with a huge non-prime product with only those two possible factors.
- If you only know the product, it takes an incredible amount of computational work to figure out what the two corresponding prime numbers are.
- So much so that it can take even the largest of supercomputers years to solve them.
Attack Surface
The more application code you have running on a system, the more physical hardware you use and the more access points you provide to them, the higher the probability you’ll have some kind of security vulnerability.
To describe this level of exposure, cybersecurity professionals use the term attack surface, which refers to the total number of entry points through which an attacker could potentially exploit a computer system.
The term also takes into account the risk of attack from insiders. For example, rogue employees who could potentially abuse their access to an IT system.
Attack surface is a particularly important concern in the cloud.
This is because cloud computing environments are dynamic. In other words, they’re continually changing, making it harder to maintain good cyber hygiene. What’s more, as users can spin up instances with just a few clicks, they can easily misconfigure them with insecure settings.
As a result, cloud security tools take a different approach from traditional on-premises solutions. Although they still detect signs of an attack, they tend to be far more strongly geared towards reducing the attack surface.
They typically help you protect your cloud by identifying:
- Unnecessary access points
- Unused instances
- Redundant storage volumes
- Weak password policies
- Obsolete user accounts
- Key changes to system configurations
The following are resources for more advanced readers with knowledge of coding or database management. They explain how three common types of cyberattack work and how to prevent them.
- Distributed Denial of Service (DDoS): This article discusses a type of attack in which hackers flood systems with huge numbers of server requests in a bid to bring them down.
- SQL Injection: Here you’ll learn how a hacker can potentially submit malicious code in the input field of a web form to delete or access sensitive information in a database.
- Cross-Site Scripting (XSS): This article explains another code injection technique, where an attacker dupes an unsuspecting user into loading a malicious script in their web browser.
- PHP Form Validation: This tutorial shows developers how to prevent code injection attacks on PHP forms.
In the next section, we look at the differences between on-premises and public cloud security in more detail.
On-Premises vs Cloud Security
In an on-premises data centre all your computing assets remain fixed pretty well most of the time. They only change significantly when you replace, upgrade or purchase new servers once in a while.
Traditional security focuses on protecting these static physical environments.
By contrast, your cloud infrastructure is a virtual environment, made up of lots of moving parts.
You’re continually spinning up, closing down, scaling up and scaling down resources as the demand on your applications changes over time. So keeping tabs on your cloud inventory, knowing what you have running at any given time, is essential to cloud security.
Moreover, just like the antivirus software we use on our home computers, traditional security uses resource-hungry scanning methods.
This is no big deal in on-premises data centre, which is exclusively for your own use. However, the cloud is shared multi-tenant infrastructure, where resource-intensive solutions can have a negative impact on other customers.
But the multi-tenant model of the cloud has another much more important implication for security.
When you host your applications within your own in-house data centre, you are responsible for all aspects of security. But, when you host them in the cloud, you hand over some of the responsibility to your cloud provider.
So, to help customers understand their security obligations when using their platforms, cloud vendors use a set of guidelines known as a shared responsibility model.
Shared Responsibility Model
Cloud vendors go to great lengths to provide a secure platform for their users, maintaining tight controls over the physical security of their data centres and the services they offer.
But they cannot be accountable for those aspects of security that are outside their control. For example, they’re not responsible for your application code or the access privileges you grant to your systems.
What a shared responsibility model does is set out the obligations of each party, so customers are left in no doubt about their role in protecting their cloud deployments.
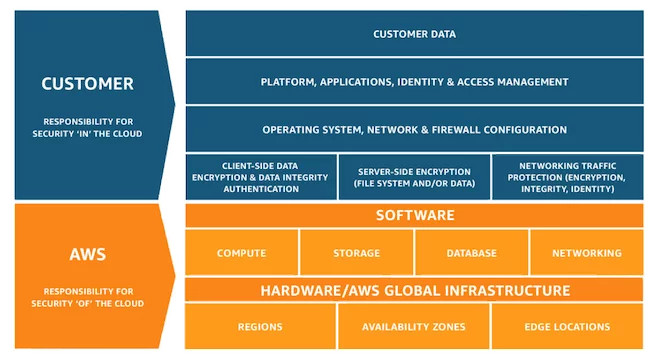
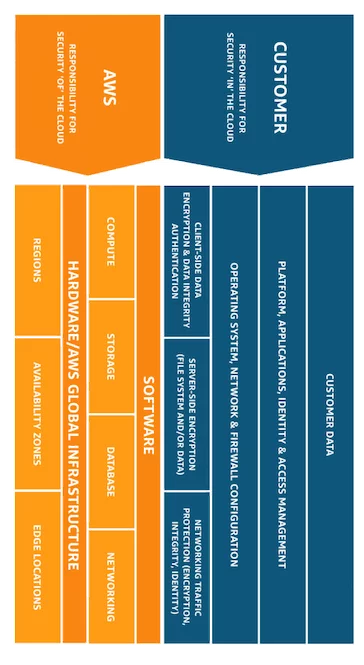
Market leader AWS takes a particularly straightforward approach to differentiating roles of responsibility, as follows:
- Security of the cloud: The aspects of security for which AWS assumes responsibility. These include its host operating system and hypervisor, the physical security of its facilities and the integrity of the tools it provides to customers.
- Security in the cloud: Your responsibilities as an IaaS customer. These include configuration of your network and other AWS services, the security of guest operating systems on your virtual machines and your own application software.
Regulatory Compliance
Many people in the IT industry mistakenly think regulatory compliance and cybersecurity are one and the same.
Although the two disciplines are closely related, compliance is much wider in scope and focuses on meeting the requirements of a specific governmental or industry body.
By contrast, cybersecurity is far less concerned with ticking boxes. Instead it focuses on the technicalities of securing your digital assets – which tend to be more specific to the individual needs of your organisation.
Big Data
Difficulty level
Skip this section
Data is fast becoming a hot commodity. And we’re generating it at an exponential rate.
Google has indexed hundreds of billions of webpages and serves more than five trillion search queries a year. Facebook currently has around three billion monthly active users.
Amazon lists more than 600 million products on its US website alone.
That’s a serious amount of data.
So how on earth do they store it all? And why don’t their services grind to a halt under the sheer volume of data?
Well, for starters, they couldn’t rely on traditional database solutions.
These were designed to run on just a single server. And not even the largest of servers has anywhere near the capacity to host such a colossal amount of data.
And another thing.
The performance of a traditional database system reduces significantly as it increases in size.
Think about it this way.
It takes longer to find a number in a telephone directory than in a short list written on a note pad.
In other words, it’s very quick to find a number in this:

But much slower in this:

Traditional databases work in exactly the same way. So the Internet giants had to come up with new solutions to get at all that data much more quickly.
They developed distributed computing systems that could replicate data across a network of servers. This meant they could spread the workload of serving vast numbers of searchers, users or customers.
Then they released their technologies to the wider world, giving other companies a way to manage data at epic scale.
Leading Big Data Technologies
Once you start writing about big data, you’ll soon become familiar with many of the open-source projects that were originally developed by the leading Internet players.
Created by Yahoo!, Hadoop is one of the most widely used big data frameworks. But Google, Facebook and LinkedIn have also made substantial contributions – with MapReduce, Cassandra and Kafka respectively.
As a result, businesses went data crazy.
Finally, they could get deeper insights into consumer behaviour, better target their marketing strategies and exploit new opportunities to improve the customer experience.
At the same time, big data technology paved the way for interconnectivity and synchronization between personal computers and handheld devices. And it’s also been the driving force behind the Internet of Things.
The Internet of Things (IoT)
The Internet of Things (IoT) is an umbrella term for the interconnected network of smart devices, machinery and appliances that are able to communicate and interact with each other over the Internet.
The technology is set to transform our daily lives and is already making an impact in applications, such as:
- Home automation
- Energy management
- Remote patient health monitoring
- Smart traffic management systems
What Is Big Data?
So what exactly is big data?
Well, there’s no hard and fast definition.
But, basically, you can distinguish it by the following three key characteristics:
- Volume: The huge scale of data.
- Velocity: The sheer speed at which you can generate and process it.
- Variety: The wide variety of data – from text and images to audio and video.
What’s more, we also know that:
- Traditional database solutions aren’t cut out to handle large volumes of data
- The Internet giants came up with distributed computing systems to overcome the problem
But that still doesn’t tell us a great deal.
So let’s take a closer look at how this all actually works.
The following key database concepts help to explain just that:
CAP Theorem
This sounds pretty heavy. So let’s keep this really simple.
CAP Theorem is a principle that describes the behaviour of different types of distributed data store. By the term distributed, we mean data that’s stored across a network (cluster) of separate machines (nodes).

CAP stands for Consistency (C), Availability (A) and Partition Tolerance (P).
Here’s what each of these terms mean.
- Consistency: Each time you read data, it’s the most up-to-date version.
- Availability: Data is readily available. In other words, every response to a read request is returned quickly and without an error.
- Partition tolerance: The data store will continue to function when there is a communication break (partition) between nodes in the cluster.

Now CAP Theorem states that a distributed data store can only guarantee two of these three properties. In other words, if you want a data store that:
- Guarantees consistency: You can also guarantee availability OR partition tolerance but NOT both.
- Guarantees availability: You can also guarantee consistency OR partition tolerance but NOT both.
- Guarantees partition tolerance: You can also guarantee availability OR consistency but NOT both.
So why is this so important in the field of big data?
Because choosing a database solution is a matter of making sacrifices.
In the case of a distributed data store, you have to have partition tolerance. If not, it would mean the whole system breaks if just one of the connections breaks.
That’s not good.
It would be like the entire rail network coming to a halt because of one failed signal.
So what’s the bottom line?
Because a big data database must be partition tolerant, it can guarantee either consistency OR availability. But NOT both.
Think about it:
- When data is updated at any one node, it must be rolled out to all the others before you can be sure it’s consistent. This introduces a delay, which means you can’t guarantee availability.
- When you make data instantly available at any one node, there could always be a more up-to-date version (on one or more other nodes) that hasn’t reached it yet. So you can’t guarantee consistency.
On the other hand, a traditional database system only has one node. If that goes down, it means the whole lot has gone down. So it isn’t partition tolerant. But data is always available and always consistent.

ACID Transactions
The best way to understand ACID transactions is to think about the potential pitfalls of an online banking system.
So imagine, for example, you’re just transferring some money from your current account into your savings.
A whole number of things could potentially go wrong:
Scenario 1
- Your current account gets debited.
- But then, just as it does so, the server goes down and your savings account doesn’t get credited.
As a result, you end up out of pocket.
Scenario 2
- You make the above transfer into your savings. But this time, a friend pays money into your current account at the same time.
- Their transaction starts first.
- It reads your initial balance figure and calculates the new balance after payment.
- Meanwhile, the online banking system starts to process your own transfer. Your friend’s payment hasn’t yet completed. So it reads the same initial balance figure as above.
- While your transfer is processing, your friend’s payment completes and writes a new higher balance to your account.
- Your transfer completes and writes the new lower balance to your account.
But here’s the problem: Your transaction used the balance figure before your friend’s payment was written to your account. While it was processing, that balance figure had changed.
So when it writes a new balance figure to your account, it is inaccurate. It hasn’t taken into account your friend’s payment that took place in the meantime.
As a result, you end up out of pocket.
Scenario 3
- Your current account gets debited and your savings account gets credited. In other words, your transfer is successful.
- A few minutes later, the online banking system crashes.
- The bank needs to rebuild its database from a backup.
- It uses a backup it took earlier in the day – before you made the transfer.
As a result, the transaction doesn’t show up in your accounts. The transfer has vanished.
ACID Properties
Of course, in reality, banking systems have safeguards in place to prevent these things from happening. They use an ACID model of database design, which maintains the integrity of all transactions.
ACID stands for:
- Atomicity: All changes in the transaction are performed OR none of them are.
- Consistency: The data remains valid after the transaction. For example, in the above scenarios, the combined total balance of your current and savings accounts should be the same before and after the transaction. Otherwise the database reverts to its previous state.
- Isolation: Simultaneous transactions do not interfere with each other and behave as if they’re processed one after another (in serial).
- Durability: Each transaction must be logged in some way before new data is committed. This ensures all database changes can be recovered in the event of a system failure.
ACID transactions are one of the key features of traditional database systems. However, all the additional controls come with a performance overhead. So some new-generation databases designed for big data do not support them.

Relational Databases
The relational database model has been the mainstay of traditional IT since it was first conceived in 1970 by British computer scientist Edgar F. Codd.
At its most basic level, a relational database is a collection of one or more tables, where:
- A table contains data organised into a series of rows and columns.
- A row represents a set of related data, such as information about a customer, known as a record.
- A record consists of fields – one for each column of the table. Each item of data is stored in a field.
- A column represents data of the same type, such as Customer ID, Name and Date of Birth, and contains one value for each row of the table.
Here’s what a very simple table might look like:

However, in many cases, a database contains more than just a single table.
For example, notice how vendor #25 appears more than once in the vendor_id column of the above table. It would be very inefficient to duplicate the full details about each vendor – especially in a large data set where they may be repeated many times over.
So a database designer would typically create a separate table as follows:

So why do we call these types of database relational?
Because a database management system would arrange the above data in storage like this:
001: 25, Premier Pharmacy Supplies, Falkirk;
002: 30, Remington UK, Manchester;
003: 31, DA Distributors, Halesowen;
004: 36, Tena, Dunstable
Mathematicians call this method of organising data a relation.
Hence the term relational database.
But, as humans, we find it much easier to visualise the same set of information in an abstracted two-dimensional form.
Hence the term table.
We’ll look at new big data alternatives to relational databases later. But, for now, here are some of the key characteristics of the traditional relational database model:
- Highly structured data: All records in any specific table contain the same clearly defined fields. At the same time, data in each field must be of the format specified for the column in which it belongs.
- ACID support: Most relational database systems come with an implementation of SQL that supports ACID transactions. So they’re primarily designed with data integrity in mind.
- Data consistency: What you read is always the most up-to-date version.
- Scaling: Deployments are limited to just a single server. So you can only scale your database vertically by upgrading your hardware. With larger databases, this can be particularly costly as you’ll need to rely on expensive high-end servers.
Although new distributed databases have evolved to handle data at massive scale, relational databases remain the best choice for many everyday applications.
They’re also still highly relevant to the big data discussion. All the more so, as new solutions are emerging that combine the data integrity of relational databases with the huge scaling capability of distributed systems.
Advanced tip: One way to improve the performance of a large relational database is to split it up into smaller, faster and more manageable parts. This Quora discussion covers the four different options.
Structured Query Language (SQL)
Structured Query Language (SQL) is the standard computer language used to communicate with virtually all relational databases.
Here’s what a very simple SQL query might look like:
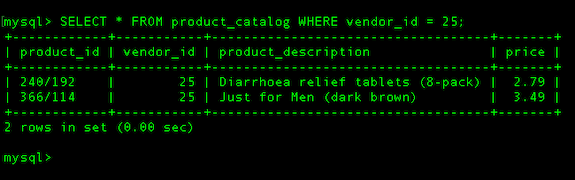
SELECT * FROM product_catalog WHERE vendor_id = 25;
And here’s the result you’d get if you performed that query on our table product_catalog above:
SQL (pronounced either SEQUEL or S-Q-L as you prefer) has become synonymous with relational databases. So people often use the names relational database and SQL database interchangeably.
If you want to learn more about SQL, or just get a better feel for how it works, then check out this tutorial at w3schools.com. You can also experiment with SQL queries if you have Microsoft Access, which comes with the desktop version of Microsoft Office for Windows and a number of Office 365 subscriptions.
Row-Based Storage
By and large, relational databases use row-based storage.
What does this mean?
If we return to the vendor_details table above, you’ll recall how we said a database system stores the data in serial like this:
001: 25, Premier Pharmacy Supplies, Falkirk;
002: 30, Remington UK, Manchester;
003: 31, DA Distributors, Halesowen;
004: 36, Tena, Dunstable
This arrangement is known as row-based storage because the information is organised on disk row by row.
Look at the first line. You’ll see that the details about Premier Pharmacy Supplies are located next to each other. The same goes for the other three vendors.
So when a database system retrieves or updates the data in a record of a row-based table, it accesses the same physically contiguous section of disk. This means row-based systems are quick and efficient at reading and writing records.
By contrast, they’re not so well geared towards querying large volumes of data.
Take our table of products we used earlier:

Imagine it were much larger and we still wanted to find all products supplied by vendor #25.
The database system would have to scan through the entire table for matching records.
That could be a seriously big workload.
And that’s why not all databases, relational or non-relational, store data this way.
Column-Based Storage
Tables in column-based systems look just like their row-based counterparts. But behind the scenes they store the data differently, grouping values by column rather than by row.
So the data in our vendor_details table would be stored like this:
25:001, 30:002, 31:003, 36:004;
Premier Pharmacy Supplies: 001, Remington UK: 002, DA Distributors: 003, Tena: 004;
Falkirk: 001, Manchester: 002, Halesowen: 003, Dunstable: 004;
Now let’s say you want to search your table for vendors in a specific location.
Look how the values for the location column are now grouped together. Your query doesn’t need to scan the entire table, but only one section of it.
This helps speed up queries and can make a huge difference as your data scales.
On the flip side, notice how the values in each record are now distributed across storage. This means that, by comparison with row-based systems, reading and writing records is much slower.
A number of different relational databases use column-based storage. But so do several types of non-relational database.
So let’s look at these in the next section.
Want to learn more about column-based storage? This Wikipedia entry covers it in more detail.
Non-Relational Databases
Non-relational database is just a general term to describe any type of database that doesn’t follow the traditional relational model.
The concept of the non-relational database is nothing new. In fact, alternative methods of structuring data were around long before the relational database existed.
But non-relational databases have seen a rapid resurgence in recent years – in response to the challenges the leading online players faced as they sought to overcome the scaling limitations of relational databases.
Non-relational databases are also known as NoSQL databases. NoSQL originally stood for non-SQL. But the term has now come to mean Not only SQL. This new meaning highlights the fact some non-relational systems are able to support SQL-like queries.
There are different types of non-relational database, which are grouped into a variety of categories and subcategories – one of which is the column-based model. The other three main classes are as follows:
Key-Value Store
The concept of the key-value store couldn’t be simpler.
Each record is made up of a unique key and a value, known as a key-value pair.
Like this:
| Key | Value |
|---|---|
| 01213896326 | Peter Green |
| 02074317412 | Jimmy Hendrix |
| 01213492123 | Eddie Hazel |
| 02080825113 | Jimmy Page |
| 01353281114 | Dave Gilmour |
| 01223623011 | Nile Rodgers |
| 01702359249 | Bootsy Collins |
| 01497428328 | Chris Shiflett |
| 01512234596 | George Harrison |
The key can be pretty well any kind of number, text string or binary sequence. However, some database systems may apply rules and restrictions.
The value can contain anything from a simple text string or number to a list, computer code or even another key-value pair. With some database management systems you also have the option to specify the data type for the value.
Unlike the relational database model, which is highly structured, a key-value database gives you the freedom to store your data any way you like.
For example, in the following data set, the value contains either a vendor name or vendor location:
| Key | Value |
|---|---|
| vendor_name:25 | Premier Pharmacy Supplies |
| vendor_location:25 | Falkirk |
| vendor_name:30 | Remington UK |
| vendor_location:30 | Manchester |
| vendor_name:31 | DA Distributors |
| vendor_location:31 | Halesowen |
| vendor_name:36 | Tena |
| vendor_location:36 | Dunstable |
Key-value stores scale well because:
- They take up less storage: Relational databases need to reserve space for optional data – whether they store a value or not. A key-value database doesn’t need to store anything if an optional value doesn’t exist.
- Data retrieval is very simple: Most key-value stores are designed for quick and simple lookups via the key. By contrast, relational databases are tailored to making slower, more complex queries across one or more table columns.
- They’re well suited to distributed systems: The simplicity of the key-value store makes it much easier to both distribute and access data across a network of nodes.

Key-value databases are a good choice for storing user profiles and website session information, such as the contents of an online shopping basket.
As key-value stores work much like a dictionary or simple two-column lookup table they’re often referred to as a dictionary or hash.
Document Store
A document-oriented database is a more sophisticated class of key-value store, taking the concept a step further by introducing the notion of a document.
In essence, a document performs much the same role as a row in a relational database table. But instead of using columns to store data about each record, it uses a set of key-value pairs.
Here’s what our vendor data might look like if it were stored in a set of documents:


As with key-value stores, documents don’t have to have the same fixed structure:


They can also store nested sets of values or nested sets of key-value pairs.
Like so:


Logical groupings of documents are organised into collections, which are the document store equivalent of a relational database table:

As with key-value stores, document stores are more scalable than their relational counterparts.
What’s more, because you can structure them how you want, it’s much easier to design a database that fits around your data.
This often means you can store all the component values of a specific data entity in a single document – rather than spreading the same information across several relational database tables.
Document-oriented databases share similar use cases to their more basic key-value counterparts and are typically used for storing product catalogues, web analytics and blog comments.
Graph Database
So far, all the databases we’ve previously seen only store data. They store what the data is (a value) and what the data represents (through its label, column name or key).
If you want to know the relationship between any of that data, you need to run a query – just like the SQL query we showed you earlier:
SELECT * FROM product_catalog WHERE vendor_id = 25;
In the above example, the relationship between the products we wanted was vendor #25 (Premier Pharmacy Supplies).
But this was a very straightforward query on a very simple data set.
So what about more complex data sets, such as a social network?
You’d have to map data to a large, highly rigid and cumbersome set of tables in order to represent the interconnections between people, likes, mentions, updates and so on.
And querying that data would be a logistical nightmare, involving time-consuming scans across a multitude of tables.
So what’s the solution?
 Well, this is where graph databases come in.
Well, this is where graph databases come in.
Graph databases are a completely different database concept.
They don’t just store data but also the connections between data.
They’re designed with relationships in mind.
And, whereas a relational database performs complex calculations and matching operations to map a relationship, a graph database simply retrieves the relationship from storage.
This makes them perfectly adapted to use cases, such as personalised product recommendations on online retail sites, fraud detection and, of course, social media.
Graph databases are based on graph theory used in mathematics – with pretty much the same concepts and terminology.
If you want to learn more about how graph databases work then check out this introduction to the graph data model by graph database management system Neo4j.
Now let’s finish this section by looking at the common features and characteristics of all non-relational databases:
- Flexible data structure: Data can be highly structured, semi-structured or unstructured. This flexibility reduces the operational overhead of enforcing data formats, streamlining database management.
- Superfast queries: By and large, non-relational databases sacrifice many traditional database features in favour of faster query performance.
- Horizontal scaling: Non-relational databases are generally suited to storing large sets of distributed data – which you can scale horizontally simply by adding more nodes. This makes them perfectly adapted to the cloud, as you can automatically add more virtual servers as your data grows.
- Query language support: There is no standard query language for non-relational databases. Instead, each type of database provides its own query mechanism through a custom API. However, many now support SQL-like queries to help encourage migration from relational databases.
And don’t forget: Your particular choice of non-relational database will come down to a trade-off between availability and consistency.
In other words, you can EITHER choose a database that guarantees:
|
|
Consistency: Each time you read data, it is the most up-to-date version. |
OR
|
|
Availability: Data is readily available. In other words, every response to a read request is returned quickly and without an error. |
But you cannot have BOTH.
Database as a Service (DBaaS)
Database as a Service (DBaaS) is currently one of fastest-growing trends in cloud computing.
DBaaS offerings are fully managed services, which automatically take care of the time-consuming tasks involved in running a database, such as:
- Infrastructure provisioning
- Scaling
- Server updates
- Backups
They help speed up application development by making it quicker and easier to set up and maintain a database in the cloud.
The leading cloud vendors offer DBaaS solutions for both relational and non-relational databases.
Right, we’re done.
But, before we wrap things up, let’s explore the opportunities for writers in this lucrative writing sector.
How to Find Freelance Writing Gigs
Cloud computing is a global business.
So your first cloud writing gig can come from practically anywhere in the world.
Because, in an industry where demand is high and supply is low, clients don’t care where you live – just as long as you can do the job.
But where do you begin?
The following are a few starting points to get your work search moving:
|
|
Update Your WebsiteJust telling the world you’re a cloud computing writer may be all you need to land your first content assignment. So update your website to include your cloud expertise and make it easy for prospects to find you. |
|
|
Revise Your Social ProfilesMany professionals in the cloud computing industry look for expert writers on social media platforms. So, likewise, make sure your profiles include information to help you show up in their searches. You should also connect with cloud professionals, such as content managers and marketing directors. Nobody wants the hard sell. So focus on building relationships and getting yourself hardwired into your new niche sector. |
|
|
Check Out Vendor MarketplacesYou can find potential clients by checking out the online marketplaces of each of the leading cloud platforms. These are catalogues of third-party cloud applications and solutions, which have been approved by the cloud vendor. You can use them to find companies that are a good match for your expertise. Once you’ve drawn up a list of targets, you can then move onto tracking down the content or marketing manager – either on LinkedIn or the company’s website. But do your research before you make any kind of approach. You should have a good understanding of what your prospects do and how you could potentially help them. Otherwise you’ll just waste their valuable time. And yours. Quick Links: |
|
|
Connect with Vendor PartnersEach cloud provider has its own network of independent accredited partners, who are able to support customers with expertise in areas such as digital transformation, hybrid cloud and application development. Just as with third-party marketplace vendors, they all need content. In particular, long-form blog posts, case studies and white papers. Quick Links: |
|
|
Reach Out to Event SponsorsYou can find leads by checking the list of sponsors or exhibitors at major cloud trade shows and conferences. If you can attend in person, you’ll also get the opportunity to meet prospects face-to-face. But remember sponsors will be busy talking to their own prospects and customers. So respect their time. |
Summing Up
Cloud computing isn’t hard to learn. Although, with so much to take in, it may seem overwhelming at first.
But here’s the good news.
A general copywriter has to familiarise themselves with a new industry practically every time they start a new project. But, as a cloud specialist, you only have to learn one.
Sure, the learning curve is steep.
Your first writing assignments will take you longer.
But, little by little, your work gets easier as you develop your knowledge.
Before you know it, you’ll become a cloud computing expert – with the technical and writing skills clients are so desperately looking for.
And, once you’ve cracked it, you’ll be in the money.
This is an entirely new world to me, but I do see that you really are working to make the cloud clearer to the lay person. This feels like a popcorn stay in during a storm read that I need to schedule soon. I look forward to more articles on the topic.
Hi Nicholas
Most of the content you find about the cloud is written by IT people for IT people. And, even though I come from a computing background myself, I still struggle to decipher much of it.
So I’m so glad you can see what I set out to achieve.
I notice you blog about photography. I wouldn’t say photographers are the most obvious readers of this post. But I’m sure a bit of cloud knowledge is useful to virtually any modern business.
Thanks for commenting.
Every line you have written in this post is easily understandable. Thanks for this amazing guide.
That was my objective Kalpana – to make a technical subject much easier to understand.
As I said to Nicholas, the problem with a lot of content about cloud computing is that it’s written by tech people. Although some are also accomplished writers, many of them aren’t.
That’s why it’s a subject that often appears more difficult than it needs to be.
All the information in one single article, what a read!
Thanks for sharing with us, I really need this….
Thanks Pallvi
I’m guessing you’ll refer back to this guide from time to time. So please let me know more about how it has helped you.
Spot on!
Whatever niche I enter, the first thing I do is learn the basics. You’ve done that here perfectly.
A quick question for you:
How did you learn copywriting? I’ve found your style to be one of the best (and most scientific).
Do you have any good resources to learn copywriting?
P.S. I’ve already read Adweek Copywriting and hand write Backlinko’s copy.
Yeah, you’re dead right Rocky, I do take a scientific approach to copywriting.
As far as building writing skills are concerned, I’ve learned progressively from a variety of sources.
These include a lot of blogs that deal with SEO, conversion optimisation, eCommerce and content marketing as much as copywriting itself.
I also note down good techniques, such as smart use of headlines, callouts and visuals, as and when I see them.
But here’s the biggest tip I can give, based on how I started out. Just take a look at the direct mail that comes through your door. That’s often where you’ll find the best examples of great copy.
Kevin, good morning from chilly Saskatchewan, Canada. Thanks for this lengthy post. Very helpful. I am thinking of narrowing my tech copywriting services to cybersecurity only.
In your opinion, how strong is the demand among infosec companies for freelance copywriters?
If there is a strong demand, do you think that getting a CompTIA Security+ certification would help me land clients?
Also, I am thinking of specializing in just blog writing for cybersecurity firms. I like the idea of having clients on a monthly retainer. Do you think that would be compelling for firms in this space, a content writer who specializes in writing blog posts for infosec firms?
Absolutely Alan
I recently did some keyword research related to writing for the cybersecurity sector; I was surprised at the amount of search volume for such a narrow niche.
As you’ll have also noticed, cybersecurity is just one of a number of areas I cover. But, based on the experience I have, it really is a high-demand, low-supply sector.
However, there is a downside to this. You may actually spend more time servicing all those new queries at the expense of ongoing client work.
As far as the certification’s concerned, I personally don’t care if a copywriter has qualifications or not.
But I’m sure many in the corporate cybersecurity world will think differently.
After all, certifications make great social proof or personal PR. So why not play the game?
I also don’t think you’ll have a problem getting work on a retainer. If a client likes your work and has sufficient demand for content then they’ll probably ask you before you ask them.
Thanks, Kevin. Much appreciated.
Please drop by again and let me know how you get on Alan.
This is totally worth reading. You have provided all the information about cloud computing in just one blog. People looking to explore this field from scratch really needs to read this once. I will look forward to more of your articles.
Great to receive a contribution from the corporate IT sector.
Please share the post around with Ducont’s HR, sales and marketing teams so those less familiar with the technology can also benefit.
hey Kevin, this is a very helpful post that you created. Cloud computing is not simple but you made it simpler for us. Not gonna lie, it was a lot to read and understand. But everything was worth it. Thanks for your gift of wisdom to us.
Hi Jacob
This ain’t no typical blog post, that’s for sure.
But it had to be long, as cloud computing is such a deep subject. And even this epic post barely scratches the surface.
As a marketing analyst and SaaS company newbie I found this piece to be very insightful. Thanks
That’s great to hear Shayur
As I said right at the start, this post is aimed at helping readers in a range of professions – including sales and marketing.
I hope I’ve delivered on that promise.
This was a very helpful post for me as I am new to cloud computing and programming. I had a freelance project recently and the article really helped me a lot for my research purpose.
I had my project from a freelance site that was my first project as a content writer, your article helped me a lot in achieving a 5-star rating.
Hi Shuja
I’m neither a fan nor a user of those online freelance marketplaces. But the most important thing is you’ve got on the first rung of the ladder and can look forward to more lucrative writing opportunities further down the line.
So glad this post has played a part in that.
Hi Kevin,
I think learning basics is important to master any niche, and the same goes for cloud computing. You have written the post in an amazing way, which is easy for readers to understand and process. Also, the “how to find writing gigs” section will definitely help a lot of people. I really loved your post. Will be referring to people in my network as well. Thanks a lot for taking the time in crafting this article in a simple to understand manner.
Hi John
If people are going to take the trouble to read through such a long post, it’s likely they’ll want to take their interest further.
That’s why I added a Where to Learn More and How to Find Freelance Writing Gigs section. So they can do just that.
And please do refer this post to people in your network. If it’s been useful to you then I’m sure it’ll be useful to many others.
Thanks for your comment.
Hey, this is a great blog post and since I’m from an IT background I find it more helpful. Thanks for sharing this masterpiece with us.
Tech writers write for tech audiences. So I love the fact readers from the IT industry have also been reading this post – not just fellow writers and marketing professionals.
Thanks Sumit
This guide provides a comprehensive overview of cloud computing, making it accessible for writers looking to specialize in this niche. The breakdown of key concepts, learning resources, and practical advice on finding freelance gigs is particularly valuable. It’s encouraging to see the emphasis on continuous learning and adapting to the dynamic nature of the cloud industry.
Hi Arif
If you happen to move into this niche then please let me know how you get on – I’d be genuinely interested.
Ahhh, at last a cloud guide that doesn’t read as if it were composed by a machine! This version presents the information in a clear and straightforward manner, ideal for those of us who are inquisitive about content! If you are considering a career in tech writing, this serves as your ideal starting point!